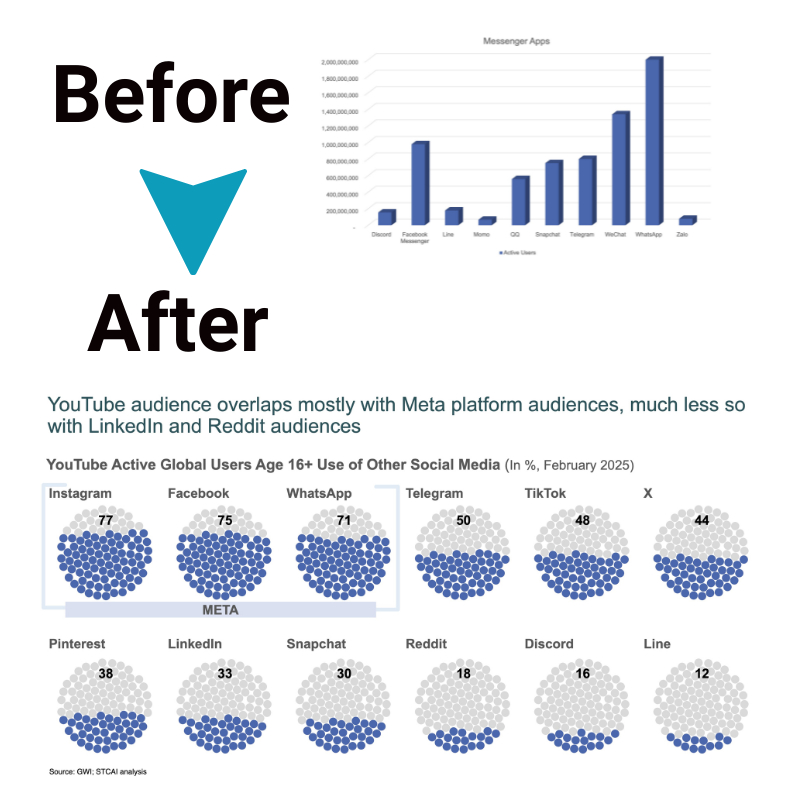
Exploratory Data Analysis: 6 Techniques for Uncovering Hidden Insights of Your Data
Exploratory Data Analysis (EDA) is a crucial first step in any data science project. It allows analysts to develop an intuition about their data, uncover hidden patterns, and identify potential issues before applying more complex machine learning algorithms. By thoroughly exploring datasets, organizations can catch issues early and make better decisions based on accurate analytics.
In this blog, we’ll overview six key techniques for exploratory data analysis and how they reveal insights hidden within data. Adopting these exploratory practices can help guide future data collection processes so models eventually fit more cleanly. Below, we’ll explore some methods for unravelling the mysteries in data!
An Overview of Exploratory Data Analysis (EDA) and its Role in Data Science
EDA refers to techniques data scientists use to analyze and investigate datasets for the first time without any strict assumptions or models. The goal is to learn what the data can tell us. EDA gives analysts the freedom to look for patterns and anomalies, test assumptions, and validate quality without restrictions.
As machine learning and AI evolve, EDA techniques become even more necessary for “debugging” data. Clean, high-quality data leads to better model performance. Tools like data profiling, statistical summaries, data visualization, and more enable organizations to explore data, find insights, and prepare for advanced analytics.
Techniques for Uncovering Hidden Insights in Your Data
Technique 1: Data Profiling
Data profiling examines datasets for statistics related to data quality, structure, relationships, etc. It can quickly uncover anomalies, formatting errors, outliers, and more. Data profiling outputs help identify the next data cleaning, transformation, and modelling steps.
Technique 2: Statistical Summaries
Statistical summaries calculate metrics like averages, dispersion, distribution, etc. They provide a high-level view of datasets. Analysts can efficiently understand ranges, patterns, and more. Statistical summaries enable simpler comparisons across datasets.
Technique 3: Correlation Analysis
Correlation analysis measures if and how strongly variables relate to each other. It’s an important step for discovering predictive relationships in data that are later used for modeling. Correlation coefficients quantify the degree of correlation and the direction (positive/negative).
Technique 4: Dimensionality Reduction
Dimensionality reduction algorithms transform datasets with many variables into lower dimensions while preserving trends. With visualization, reduced dimensions uncover relationships between variables hidden in high dimensions. Examples include principal component analysis, t-SNE, and autoencoders.
Technique 5: Outlier Detection
Outliers are data points distinctly different from others. To avoid skewed analytics, data scientists need to detect and handle outliers. Exploring distributions, distances, and densities in data enables identifying anomalies. Common analysis techniques include classification algorithms, proximity-based methods, clustering, etc.
Technique 6: Trend Identification
Identifying trends helps analysts spot patterns over time, across categories, and within subsets. Data visualization tools are essential for trend analysis. Examples include line charts, scatter plots, heat maps, dendrograms, Sankey diagrams, and more. The goal is to explore data for deeper insights.
Conclusion
Exploratory analysis is a data science pillar that enables smarter analytics. Leveraging data profiling, statistical summaries, correlation analysis, dimensionality reduction, outlier detection, and trend identification allows analysts to develop intuition, find hidden insights, and improve data quality.
EDA is an iterative process that allows analysts to incrementally deepen their data comprehension. Organizations that foster strong exploratory practices will enhance data-driven decision-making and get the most ROI from analytics.





